Additional material related to the paper:
Can virtual agents be used as a diagnostic tool:
a proof of concept study in the field of major depressive disorders
PHILIP
P.(1-2), MICOULAUD-FRANCHI J.A.(1-2), SAGASPE P.(1-2),
de SEVIN E.(2),
OLIVE J.(2), BIOULAC S.(1-2-3) and
SAUTERAUD A.(1-2)
(1) Services d'explorations fonctionnelles du système nerveux,
Clinique du sommeil, CHU de Bordeaux,
Place
Amélie
Raba-Léon, 33076 Bordeaux, France
(2) USR CNRS 3413 SANPSY, CHU Pellegrin, Université de Bordeaux,
France
(3) Pôle Universitaire Psychiatrie Enfants et Adolescents, Centre
Hospitalier Charles Perrens,
121
rue
de la Béchade, 33076 Bordeaux, France
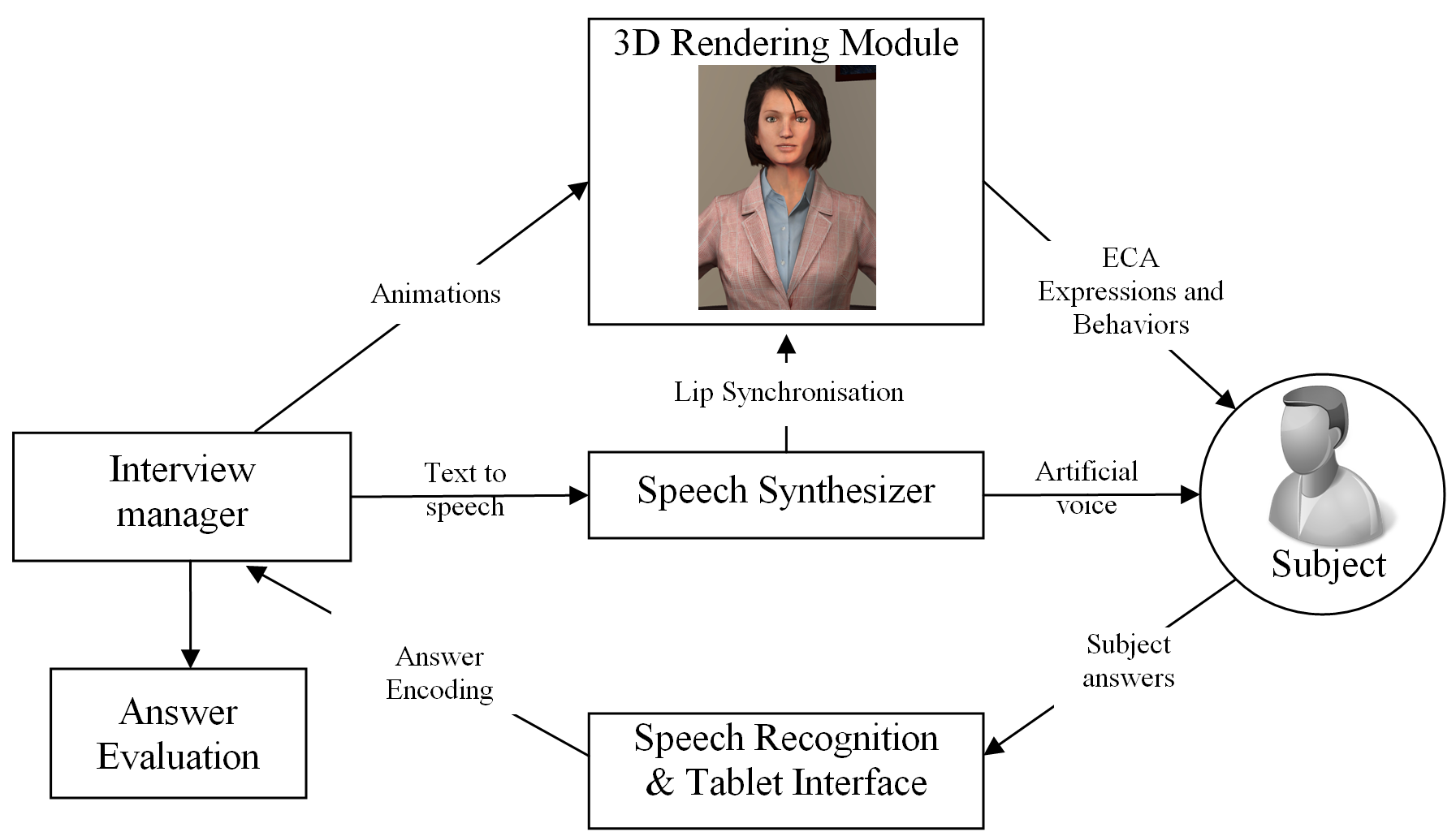
Technological steps to create Virtual Agents
The ECA system used in the present study is based on
four software modules that we already used in a previous study:
Philip P, et al. Could a Virtual Human be used to Explore Excessive
Daytime Sleepiness in Patients? Presence: teleoperators and virtual
environments. 2014;23(4):369-376. The first and main module is defined
as the interview manager. It conducts the whole interview (questions,
expected answers, scripted gestures and scripted emotions) and manages
the other modules. Instead of scripted behaviors, this module
generates ECA behaviors based on predefined or random rules. All
interviews are stored in XML files. The second module is a 3D
rendering module. Its role is to display our ECA and play animations
on command. It was created with Unity3D (Unity-Technologies, 2014), a
3D gaming engine, and it uses 81-bone 3D characters from Rocketbox
Libraries (RocketBox-Libraries, 2014). The characters can be animated
in terms of gestures, facial expressions and visemes (facial
expressions corresponding to enunciation of phonemes). The third
module operates the tablet interface and the speech recognizer. We use
the speech recognition module from Microsoft Kinect SDK (Microsoft,
2014). The tablet interface is designed to assure the continuity of
the system if the speech recognition fails by clicking the answer on
the tablet. The interview manager feeds this module with dictionaries
containing expected answers from participants. Answers of participants
after analysis are transmitted to the interview manager. The fourth
and last module is a speech synthesizer. It creates ECA speech sent by
the interview manager and, for each enunciated phoneme, sends the
corresponding viseme command to the 3D rendering module. These four
modules are thread-independent. Modules communicate by TCP sockets
that can be distributed to several computers. The ECA software suite was installed on a standard
gaming computer (Windows 8 - i7 3770@3.4GHz - 8 GB - NVidia 670 GTX)
connected to a 40-inch display. As input device we used exclusively
the Microsoft Kinect sensor for voice recognition and to monitor the
user's head. The figure above describes the overall design and
interactive mode of the ECA. ECA architecture and interactions: Architecture of the Embodied Conversational Agent used
to self-conduct interactive face-to-face clinical interviews based on Major Depressive Disorder
DSM-5 criteria.
The face to face clinical interview
Virtual human software: